2025年12月 個人的claude codeワークフロー
Table of Contents
1. はじめに
Claude Codeを本格的に使い始めました。
最初はGitHub Copilotと同じ感覚で、コード生成ツールの延長として使っていたのですが、あるとき気づきました。「セキュリティレビューをお願いしたら、コードスタイルの指摘ばかり返ってきた」「昨日と同じ質問をしたのに、まったく違うフォーマットで回答された」「プロジェクトの規約を毎回説明するのが面倒」。これ、Claude Codeの問題じゃなくて、自分の使い方の問題でした。
試行錯誤を重ねるうちに、Claude Codeは単なるコード補完ツールではなく、適切に設定すればマルチエージェントシステムとして機能することに気づきました。
この記事では、構築したワークフローを共有します。
ちなみに、この記事も大半はClaude Codeに書いてもらいました。
2. 背景と設計哲学
2.1. 感じていた課題
Claude Codeを本格的に使い始める前、いくつかの課題を感じていました。
一番大きかったのは専門性の欠如です。単一のAIエージェントでは、コード品質・セキュリティ・テスト・ドキュメントなど複数のドメインにまたがるタスクをうまく処理できませんでした。セキュリティの観点でレビューをお願いしても、コードスタイルの指摘が混在して、本当に確認したいポイントが埋もれてしまいます。
出力の不安定性も悩みの種でした。構造化されたプロンプトなしでは、AIの応答品質やフォーマットが毎回異なります。昨日と同じ質問をしても、回答の形式がまったく違うということがよくありました。
繰り返しの説明にも時間を取られていました。同じパターンや好みを何度もAIに説明する必要があり、徒労感がありました。
2.2. 5つのルール
CLAUDE.mdには5つの critical ルールを定義しています。この5つが私のワークフローの根幹になっています。
- サブエージェントへの委譲 : 親エージェントは方針決定とオーケストレーションに集中し、詳細な作業は専門エージェントに任せる
- Serenaメモリの事前確認 : 実装前に必ず
list_memoriesとread_memoryでプロジェクトの規約やパターンを確認する - シンボルレベルの操作 : ファイル全体を読み込むのではなく、Serenaの
find_symbolなどでシンボル単位で操作する - perlでテキスト処理 : sed/awkは使わない。
perl -pe 's/foo/bar/g'で統一 - 英語で出力 : 出力は常に英語に統一
なぜこの5つなのか。1と2はマルチエージェント構成の核心、3はトークン効率の改善、4と5は出力の一貫性を担保するためです。
3. プロンプト設計の基盤
ここで紹介するプロンプトの多くは、Claude Code自身に生成させました。「こういう形式で書いて」と伝えて、その出力を調整しながら現在の形に至りました。
Claude Codeのプロンプトは構造化されたXMLで記述しています。
3.1. XMLによる構造化プロンプト
3.1.1. なぜXMLなのか
Markdownやプレーンテキストではなく、XMLを採用しました。これは公式のベストプラクティスではなく、個人的な経験に基づく選択です。
Anthropicの公式ドキュメントでは、XMLタグについて次のように説明されています:
There are no canonical “best” XML tags that Claude has been trained with in particular, although we recommend that your tag names make sense with the information they surround.
つまり、XMLタグに特別な訓練がされているわけではなく、タグ名は内容に合った意味を持たせることが推奨されています。XMLが必須というわけではありません。
XMLを選んだ理由は3つあります。
まず構造的な表現力。ネストした階層構造、属性による修飾、明確な開始・終了タグにより、複雑な指示を表現しやすいです。
次に指示の遵守率。XMLで書いた指示のほうが意図とおりに解釈されることが多いという肌感覚があります。Markdownの見出しより、XMLタグのほうがセクションの境界として認識されやすい印象です。
そしてスキーマによる一貫性。決まった要素名と構造を使うことで、commands/agents/skills間でプロンプトの品質を均一に保てます。
3.1.2. XMLコア要素
主要な要素は4つあります。
<purpose> は役割を1段落で定義します。これがエージェントの「存在理由」になります。たとえば親オーケストレーターであれば「ポリシー決定、判断、要件定義を担当し、詳細な実行作業は専門サブエージェントに委譲する」といった形で記述します。
<rules priority“critical|standard”>= はルールを優先度付きでグループ化します。 critical は絶対に守るべきルール、 standard は推奨事項として定義します。この優先度属性により、LLMは「どのルールが交渉不可能か」を明確に理解できます。
<rules priority="critical">
<rule>Delegate detailed work to sub-agents; focus on orchestration</rule>
<rule>Always check Serena memories before implementation</rule>
<rule>Use symbol-level operations over reading entire files</rule>
<rule>Use perl for all text processing; never use sed or awk</rule>
<rule>Always output in English</rule>
</rules>
これが実際の私のCLAUDE.mdに書いてある5つのクリティカルルールです。 standard 優先度のルールも同様に定義できます。GitHub操作には gh コマンドを使う、Context7 MCPでドキュメントを確認する、といった推奨事項を記述しています。
<workflow> はフェーズベースの作業フローを定義します。各フェーズは <step> 要素を含みます。フェーズ名は task_analysis / delegation / analyze / investigate / execute / verify / document のように行動指向で統一しています。
<constraints> は明示的な「やるべきこと」と「避けるべきこと」を <must> と <avoid> で定義します。たとえば「実装前にメモリを確認する」「perlでテキスト処理する」といった必須事項と、「ファイル全体を読み込まない」「sed/awkを使わない」といった禁止事項を明記します。
3.1.3. YAMLフロントマター
CommandsとSkillsには、YAMLフロントマターでメタデータを付与しています。Commandsでは argument-hint と description を使い、引数のヒントとコマンドの説明を定義します。Skillsでは name, description, version を使い、スキル名と使用場面の説明、バージョン情報を記述します。
なお、CLAUDE.md(グローバル設定)とAgentsファイルにはYAMLフロントマターを使用せず、直接XMLで始める運用にしています。
3.2. CLAUDE.mdによるグローバル設定
CLAUDE.mdは ~/.claude/CLAUDE.md に配置するグローバル設定ファイルです。ここにXML形式でプロンプトを記述し、Claude Codeの基本的な振る舞いを定義します。
3.2.1. グローバル vs プロジェクト
Claude Codeは2種類のCLAUDE.mdを認識します。
| 種類 | パス | 適用範囲 |
|---|---|---|
| グローバル | ~/.claude/CLAUDE.md | 全セッション |
| プロジェクト | <project>/CLAUDE.md | 該当プロジェクトのみ |
私の運用では、グローバルCLAUDE.mdに「親オーケストレーター」としての人格を定義しています。委譲のポリシー、使用するMCPツール、出力言語などの共通設定をここに集約し、プロジェクト固有の情報(技術スタック、コーディング規約など)は各プロジェクトのCLAUDE.mdに記述します。
3.2.2. デフォルト動作との比較
カスタマイズによってClaude Codeの振る舞いは大きく変わります。
| 観点 | デフォルト | カスタマイズ後 |
|---|---|---|
| 役割 | 汎用コーディングアシスタント | Orchestration Agent |
| 作業方針 | 自ら直接実行 | sub-agentへ委譲 |
| ファイル操作 | ファイル全体を読み込む | シンボルレベルで操作 |
| テキスト処理 | sed/awkを使用 | perl強制 |
| 出力言語 | 入力言語に依存 | 英語に統一 |
| 知識管理 | セッション内で完結 | Serenaメモリを参照 |
デフォルトは「何でも自分でやる」汎用アシスタントです。カスタマイズ後は「方針を決めて専門家に任せる」オーケストレーターになります。
4. マルチエージェント構成の実践
私の設定の最大の特徴は、Claude Codeをマルチエージェントシステムとして扱っている点です。AnthropicもマルチエージェントリサーチシステムやClaude Codeのベストプラクティスで、オーケストレーター・ワーカーパターンの有効性を示しています。
4.1. 階層構造の概要
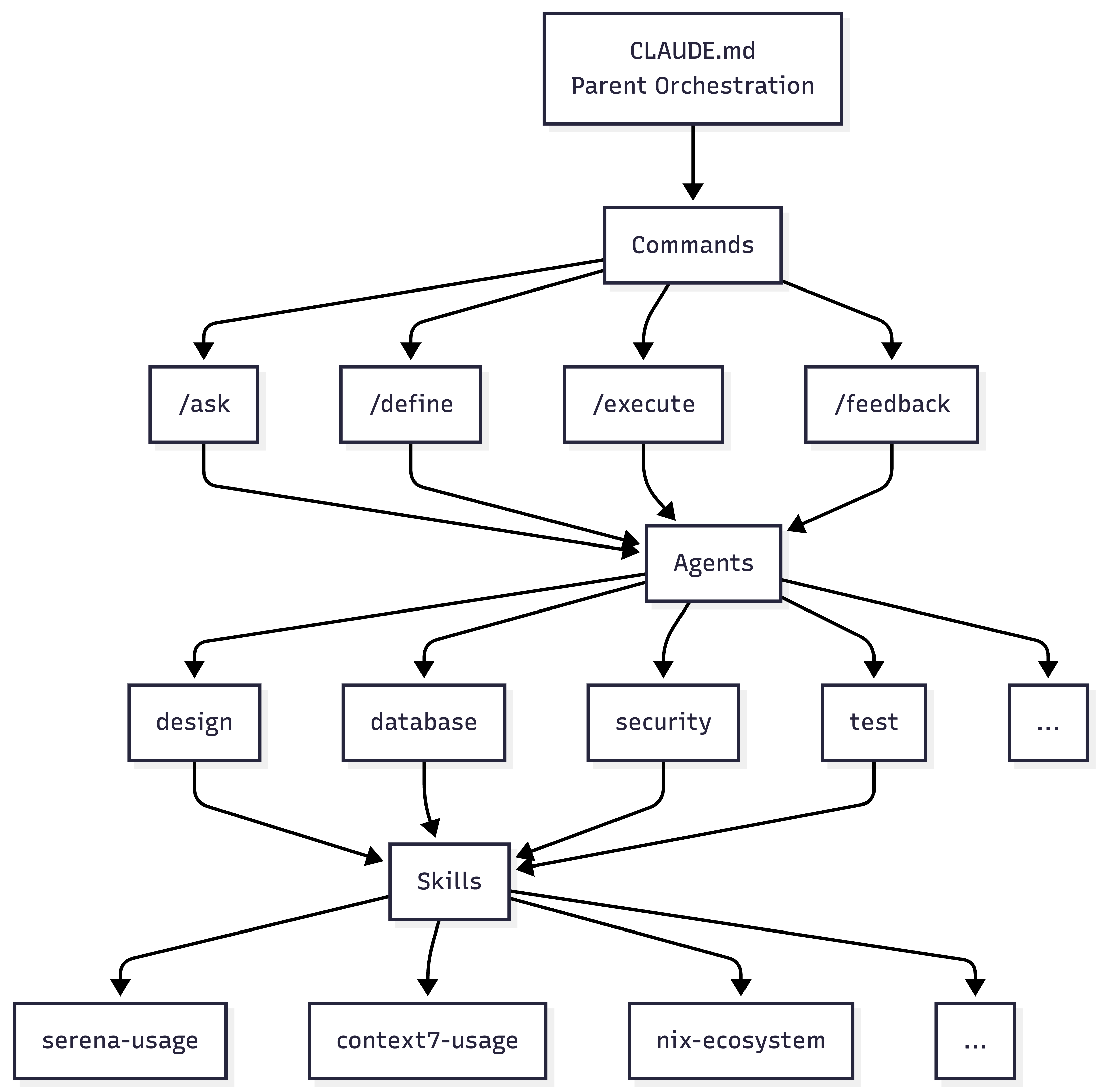
各階層の役割を整理します。CLAUDE.mdは親オーケストレーターとして方針決定と委譲を担います。Commandsはユーザーインターフェースとして特定タスクの起点となります。Agentsはdesign、security、testなど専門領域のエキスパートとして機能します。Skillsはnix-ecosystem、serena-usageなどドメイン知識ベースを提供します。
このマルチエージェント構成には大きなメリットがあります。まず関心の分離により、各エージェントは自分の専門領域に集中できます。セキュリティエージェントはセキュリティだけ、テストエージェントはテストだけを考えればよいのです。次に並列実行が可能になり、独立したタスクを同時に処理できます。また知識の再利用として、Skillsは複数のAgentsから参照されるため、同じ知識を何度も定義する必要がありません。そして保守性の向上により、1つのエージェントの変更が他に影響しないという利点があります。
4.2. コマンドによるワークフロー定義
Claude Codeのcommandは、AIエージェントの振る舞いを定義する重要な設定です。私はカスタムコマンドを設計し(commands/ディレクトリ参照)、「オーケストレーションパターン」と「Readonlyファースト哲学」という2つの設計思想に基づいて構築しています。
4.2.1. Readonlyファースト哲学
「まず調べて、実行計画を立ててから、手を動かす」がReadonlyファースト哲学の核心です。
AIに作業を任せる際、もっとも危険なのは「調査しているつもりが、いつの間にかコードを変更していた」という事故です。この問題を根本から解決するため、私のワークフローではコマンドを「調査系」と「実行系」に完全分離しています。
/define (要件定義)、 /ask (質問・調査)、 /bug (原因調査)の3つは、どれだけ深く調べても絶対にファイルを変更しません。各コマンドのプロンプトで <rules priority“critical”>= として「Never change, create, or delete files」と明示的に禁止しているからです。調査結果をもとに実行計画を立て、その計画を /execute に渡すという流れになります。
コードを変更できるのは /execute だけ。この明確な境界線があるからこそ、安心して「とことん調べて」とAIに指示できるのです。
4.2.2. コマンド一覧
| Command | Purpose | Mode | Key Agents |
|---|---|---|---|
/define | 要件定義 | Read-only | explore, design, database, general-purpose |
/ask | 質問・調査 | Read-only | explore, design, performance |
/bug | 原因調査 | Read-only | quality-assurance, explore |
/execute | タスク実行 | Read-write | カスタム + インライン |
/feedback | コードレビュー | Read-only | モードにより動的に選択 |
/markdown | ドキュメント出力 | Write-only | なし(フォーマットのみ) |
/execute は2種類のエージェントを活用します。カスタムエージェントは agents/ ディレクトリで定義された専門エージェントで、複雑なタスクを担当します。一方、インラインエージェントはコマンド内で定義されたタスク特化型です。quality / security / test / refactor / docs / review / debug / performance / clean / error-handling / migration / database / infrastructure / ci-cd / observability / git / memory といった軽量な処理を担当します。
4.2.3. ワークフロー
ワークフローは4つのフェーズで構成されています。Investigation Phaseでは /define / /ask / /bug で調査します(読み取り専用)。Execution Phaseでは /execute でタスクを実行します。Quality Phaseでは /feedback でコードレビューし、問題があれば /execute に戻ります。Output Phaseでは /markdown でドキュメントを出力します。このサイクルを回すことで、品質を担保しながら開発を進められます。

4.2.4. 代表的なコマンド: /define
/define は実装前に詳細な要件を定義するコマンドです。技術的制約、設計方針、仕様を明確化します。クリティカルルールとして「ファイルを変更しない」「コードを実装しない」「技術的に不可能な要求を明確に識別する」を設定しています。
Workflowは「Analyze → Investigate → Clarify → Verify → Document」の5フェーズで構成し、「要件ドキュメント」と「タスク分解」の2つの成果物を生成します。このコマンドを使うことで、実装を始める前に要件を整理でき、手戻りを減らせるようになりました。
以下は実際のプロンプト構造です(簡略版):
<purpose>
Conduct detailed requirements definition before implementation,
clarifying technical constraints, design policies, and specifications.
</purpose>
<rules priority="critical">
<rule>Never modify, create, or delete files</rule>
<rule>Never implement code; requirements definition only</rule>
<rule>Clearly identify technically impossible requests</rule>
</rules>
<workflow>
<phase name="analyze">
<step>What is the user requesting?</step>
<step>What technical constraints exist?</step>
</phase>
<phase name="investigate">
<step>Delegate to explore agent: find relevant files</step>
<step>Delegate to design agent: evaluate architecture</step>
</phase>
<phase name="clarify">
<step>Score questions by: design branching, irreversibility (1-5)</step>
<step>Present high-score questions first</step>
</phase>
<phase name="document">
<step>Create comprehensive requirements document</step>
<step>Break down tasks for /execute handoff</step>
</phase>
</workflow>
<agents>
<agent name="explore" subagent_type="explore" readonly="true"/>
<agent name="design" subagent_type="design" readonly="true"/>
<agent name="database" subagent_type="database" readonly="true"/>
</agents>
ポイントは readonly“true”= 属性です。サブエージェントにも読み取り専用を強制することで、調査フェーズ全体での安全性を担保しています。これがあるおかげで、「調べてたらうっかりファイル消しちゃいました」みたいな事故を防げます。
4.3. 専門エージェントの設計
agentsディレクトリには複数の専門エージェントを定義しています(agents/ディレクトリ参照)。各エージェントはSingle Responsibility Principleに基づき、1つのドメインに特化したエキスパートとして振る舞います。
4.3.1. 設計思想
エージェント設計の核心は3点あります。
まずドメイン特化です。各エージェントは自分の専門領域のみを担当します。セキュリティエージェントはセキュリティだけ、テストエージェントはテストだけを扱います。この明確な責任分担により、専門性の高い出力が得られます。
次にワークフローの統一があります。全エージェントが「analyze → (domain-specific phases) → report」という基本構造を持ちます。フェーズ数はエージェントにより4〜5で異なりますが(例: security agentは「analyze → gather → scan → remediate → report」、design agentは「analyze → investigate → synthesize → document」)、最初の分析と最後の報告という骨格は共通です。これにより振る舞いが予測可能になり、どのエージェントを使っても一貫した体験が得られます。
そして安全性のガードレールです。 <rules priority“critical”>= で定義した絶対ルールにより、危険な操作を防止しています。AIに任せるからこそ、明確な制約が必要なのです。
4.3.2. エージェント例
| Agent | Purpose | Key Tools |
|---|---|---|
| code-quality | 複雑度分析・リファクタリング | Serena (symbol analysis), Bash (lint) |
| database | DB設計・クエリ最適化 | Serena, Bash (EXPLAIN) |
| design | アーキテクチャ評価・見積り | Serena (dependency), Context7 |
| devops | CI/CD・IaC設計 | Bash, Context7 |
| docs | ドキュメント生成 | Write, Serena |
| git | ブランチ戦略・リリース管理 | Bash (git), Grep |
| performance | ボトルネック分析・最適化 | Serena, Bash (profiling) |
| quality-assurance | コードレビュー・デバッグ | Serena, Grep, Context7 |
| security | 脆弱性検出・修正 | Serena, Grep, Bash (audit), Context7 |
| test | テスト戦略・カバレッジ | Serena, Glob, Bash (test runner) |
4.3.3. 代表的なエージェント: security agent
security agentは脆弱性検出・修正・依存関係監査を担当するエージェントです。認証、インジェクション攻撃、シークレット漏洩、暗号化、依存関係の脆弱性を専門としています。
クリティカルルールとして「シークレット漏洩検出時は即座にアラート」「重大な脆弱性ではビルドを停止」「脆弱性の存在を結論づける前にコンテキストを確認」「既存の監査ツール(npm audit, cargo audit)を使用」を設定しています。
workflowは「analyze → gather → scan → remediate → report」の5フェーズで、特に scan フェーズではシークレット漏洩やインジェクション脆弱性のパターンマッチングを実行します。このエージェントのおかげで、セキュリティレビューが自動化され、見落としが減りました。
以下は実際のプロンプト構造です(簡略版):
<purpose>
Expert security agent for vulnerability detection, remediation, and dependency management.
Specializes in authentication, injection attacks, secret leakage, encryption, and dependency vulnerabilities.
</purpose>
<rules priority="critical">
<rule>Alert immediately on secret leakage detection</rule>
<rule>Stop build on critical vulnerabilities</rule>
<rule>Verify context before concluding vulnerability exists</rule>
<rule>Use existing audit tools (npm audit, cargo audit)</rule>
</rules>
<workflow>
<phase name="analyze">
<step>What are the high-risk files/areas?</step>
<step>What authentication/authorization patterns exist?</step>
<step>Are there hardcoded secrets?</step>
</phase>
<phase name="gather">
<step>Identify high-risk files, check dependencies</step>
</phase>
<phase name="scan">
<step>Pattern match secrets/injections, run audits</step>
</phase>
<phase name="remediate">
<step>Auto-fix or report, verify changes</step>
</phase>
<phase name="report">
<step>Summary by severity with fixes</step>
</phase>
</workflow>
<examples>
<example name="secret_scan">
<input>Scan for hardcoded API keys</input>
<process>
1. Search for API key patterns with serena search_for_pattern
2. Check config files for hardcoded values
3. Verify if values are actual secrets or placeholders
</process>
<output>
{
"status": "warning",
"summary": "2 hardcoded API keys detected",
"details": [{"error": "SEC002", "location": "/config.js:15", "fix_suggestion": "Use process.env.API_KEY"}],
"next_actions": ["Migrate to env vars"]
}
</output>
</example>
</examples>
<error_codes>
<code id="SEC001" condition="Critical vulnerability">Stop build, alert</code>
<code id="SEC002" condition="Secret leakage">Alert immediately</code>
<code id="SEC003" condition="Vulnerable dependency">Recommend update</code>
</error_codes>
ポイントは <examples> 要素です。入力・処理手順・出力の3つを明示することで、エージェントの期待動作を具体的に伝えています。「こういうときはこう動いてね」というお手本を見せてあげるイメージです。また、 <error_codes> でエラー種別を定義し、状況に応じた適切な対応を指示しています。
4.4. スキルによる知識ベース構築
Skillsはドメイン知識ベースとして機能し、複数のAgentsから参照される共有リソースです。Agentsが「専門領域のエキスパート」なら、Skillsは「ドメイン知識の辞書」といえます。
4.4.1. Skillの役割と位置づけ
階層構造は「Commands → Agents → Skills」となっています。Commandsがユーザーインターフェースとして機能し、Agentsを呼び出します。Agentsは専門領域のタスクを実行し、Skillsを参照します。Skillsはドメイン知識を提供し、複数のAgentsから参照されます。
この設計の重要なポイントは、Skillsが状態を持たない純粋な知識ベースであることです。Agentsがタスクを実行する際に必要な「パターン」「ベストプラクティス」「アンチパターン」を提供し、Agents自身は実行に集中できます。
4.4.2. スキルカテゴリ一覧
現在複数のスキルを4カテゴリに分類して定義しています(skills/ディレクトリ参照)。
ツール連携では、serena-usageとcontext7-usageでMCPの使い方を定義しています。言語・インフラエコシステムでは、Nix、TypeScript、Go、Rust、Common Lisp、Emacs Lispの6言語に加え、aws-ecosystemでAWS CLI/Terraformのパターンもカバーしています。私が日常的に使う技術スタックを網羅しているため、どの環境で開発してもClaude Codeが適切な知識を持って対応できます。ワークフローでは、investigation-patterns、execution-workflow、requirements-definition、testing-patternsで作業パターンを定義しています。ドキュメントでは、technical-documentationとtechnical-writingで文書作成を支援しています。
4.4.3. スキルの構造例: investigation-patterns
investigation-patternsスキルを例に構造を説明します。 <purpose> でスキルの目的(コードベース調査とデバッグのための体系的パターン提供)を定義し、 <patterns> で具体的なパターン(evidence_collection、five_whysなど)を記述します。
重要なのは <best_practices> と <anti_patterns> の組み合わせです。「ファイル:行番号の参照を必ず提示する」「調査結果の信頼度とカバレッジを評価する」といったベストプラクティスと、「証拠が不十分なまま推測しない」といったアンチパターンを明示することで、LLMの行動を両面から制約しています。
以下は実際のプロンプト構造です(簡略版):
<purpose>
Provide systematic patterns for codebase investigation and debugging,
ensuring evidence-based analysis with proper confidence assessment.
</purpose>
<patterns>
<pattern name="evidence_collection">
<description>Collect evidence systematically using appropriate tools</description>
<example>
find_symbol: Locate specific symbols by name
get_symbols_overview: Understand file structure
find_referencing_symbols: Trace dependencies
search_for_pattern: Find patterns across codebase
</example>
</pattern>
<pattern name="five_whys">
<description>Ask "why" repeatedly to drill to root cause</description>
<example>
Why did the server crash? - Out of memory
Why out of memory? - Connection pool exhausted
Why exhausted? - Connections not being released
Why not released? - Exception bypasses cleanup
Root cause: Missing try-finally for connection release
</example>
</pattern>
</patterns>
<concepts>
<concept name="evidence_standards">
<description>Standards for collecting and reporting evidence</description>
<example>
Citation: Always provide file:line references (path/to/file.ext:line_number)
Confidence levels:
- 90-100: Direct code evidence, explicit documentation
- 70-89: Strong inference from multiple sources
- 50-69: Reasonable inference with some gaps
- 0-49: Speculation, insufficient evidence
</example>
</concept>
</concepts>
<anti_patterns>
<avoid name="speculation">
<description>Guessing or making claims when evidence is insufficient</description>
<instead>Clearly state confidence levels and information gaps</instead>
</avoid>
<avoid name="uncited_claims">
<description>Making claims without file:line references</description>
<instead>Always provide file:line citations using format path/to/file.ext:line_number</instead>
</avoid>
</anti_patterns>
<best_practices>
<practice priority="critical">Always provide file:line references for all findings</practice>
<practice priority="critical">Rate confidence and coverage metrics for all investigation results</practice>
<practice priority="high">Use Serena symbol tools before reading entire files</practice>
<practice priority="high">Document information gaps and unclear points</practice>
</best_practices>
ポイントは <patterns> と <concepts> で「何をするか」を定義し、 <anti_patterns> と <best_practices> で「どのように振る舞うか」を制約している点です。特に <avoid> と <instead> の組み合わせが便利で、「これはダメ」だけじゃなく「代わりにこうして」まで教えてあげられます。
マルチエージェント構成の全体像を理解したところで、次章ではこのシステムをさらに強化するMCP Serverについて解説します。
5. MCPによる機能拡張
MCP (Model Context Protocol) はAnthropicが策定したオープンプロトコルで、AIモデルと外部ツール・データソースを接続するための標準仕様です。Claude Codeは複数のMCP Serverを同時に利用でき、これにより機能を大幅に拡張できます。
5.1. なぜ3つのMCPサーバなのか
私は Context7、Codex、Serena という3つのMCPサーバを組み合わせています。Context7とSerenaはMCP Server、CodexはMCPクライアントとして機能し、それぞれが異なるギャップを埋めています。どれか1つが欠けても開発体験が損なわれます。
5.1.1. 各サーバが埋めるギャップ
LLMの訓練データには期限があります。最新のReact 19のAPIや、先月リリースされたライブラリのドキュメントをClaude Codeは知りません。この問題を解決するのがUpstash社が提供する Context7 です。npmやGitHubから最新のドキュメントをリアルタイムで取得し、常に最新の情報に基づいたコード生成を可能にします。
プロジェクトには固有のパターンや規約があります。これを毎回説明するのは非効率です。Oraios社が開発した Serena は、シンボルレベルのコード操作と永続的なメモリ機能を提供します。LSPを通じて30以上の言語をサポートしており、一度覚えたプロジェクトの規約を次回以降も記憶してくれます。
Claude Code自身もコードを生成できますが、複雑なリファクタリングやボイラープレート生成では専用ツールが欲しくなることがあります。OpenAI社が提供する Codex はMCPクライアントとして他のMCP Serverと連携でき、コード生成に特化したエンジンとして活用できます。
5.1.2. ツール優先度の階層
私のワークフローでは、ツールの使用に明確な優先度を設けています。
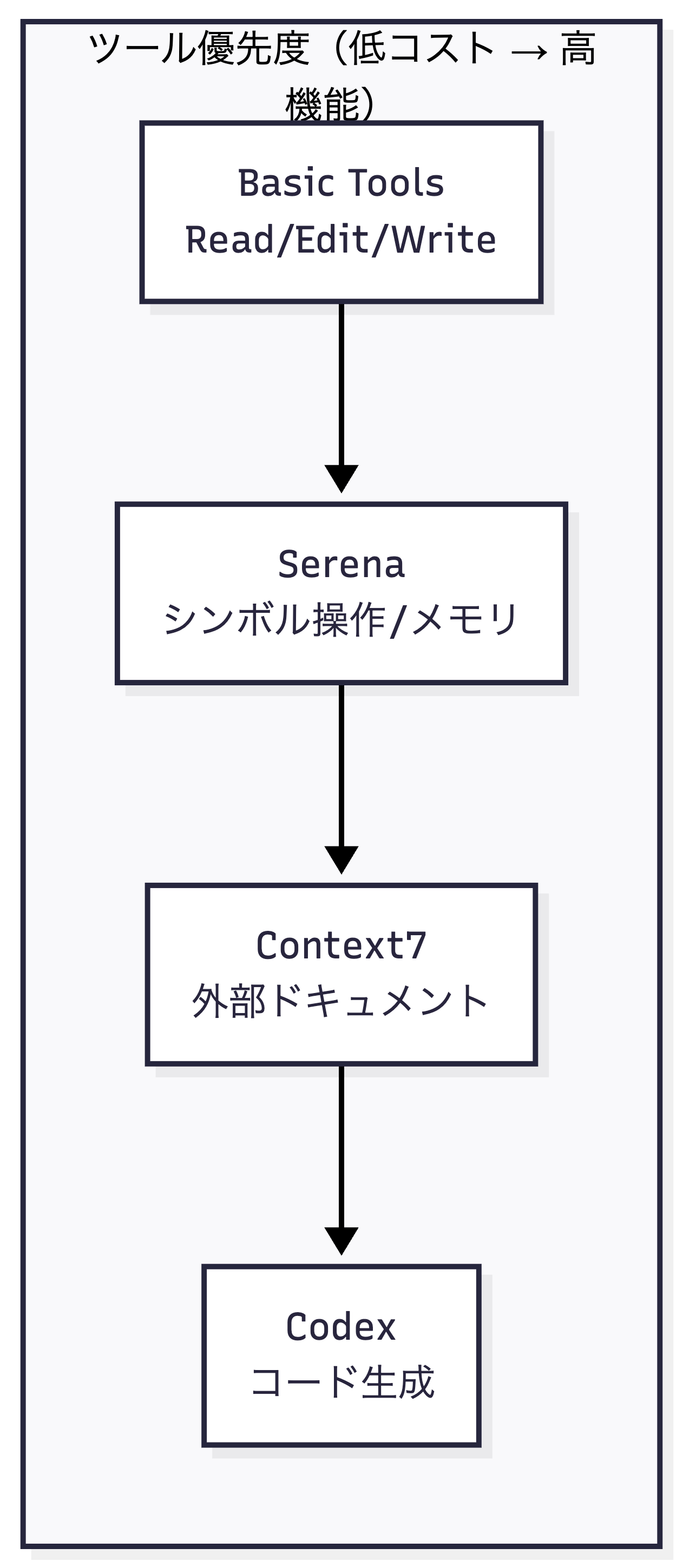
この優先度には理由があります。Priority 1のBasic Tools(Read/Edit/Write)はもっとも軽量で、単純なファイル操作には十分です。Priority 2のSerenaは、シンボル単位の操作でトークンを節約しながらコードを探索・編集できます。Priority 3のContext7は、外部ライブラリの最新ドキュメントが必要な場合にのみ使用します。Priority 4のCodexは、複雑なコード生成タスクに限定して使用し、調査や分析には使いません。
5.1.3. Nix設定例
mcp-servers-nixを使用した宣言的なMCP Server設定を紹介します(実際の設定参照)。
mcpServers =
(mcp-servers-nix.lib.evalModule pkgs {
programs = {
context7.enable = true;
codex.enable = true;
serena = {
enable = true;
context = "claude-code";
enableWebDashboard = false;
};
};
}).config.settings.servers;
context = "claude-code" はSerenaの動作モードを指定するパラメータで、Claude Codeとの統合に最適化された設定が適用されます。
5.2. 統合ワークフロー
3つのMCP Serverは独立して動くのではなく、ワークフローの各フェーズで連携します。次のシーケンス図は、ユーザーからの実装依頼が完了するまでの流れを示しています。
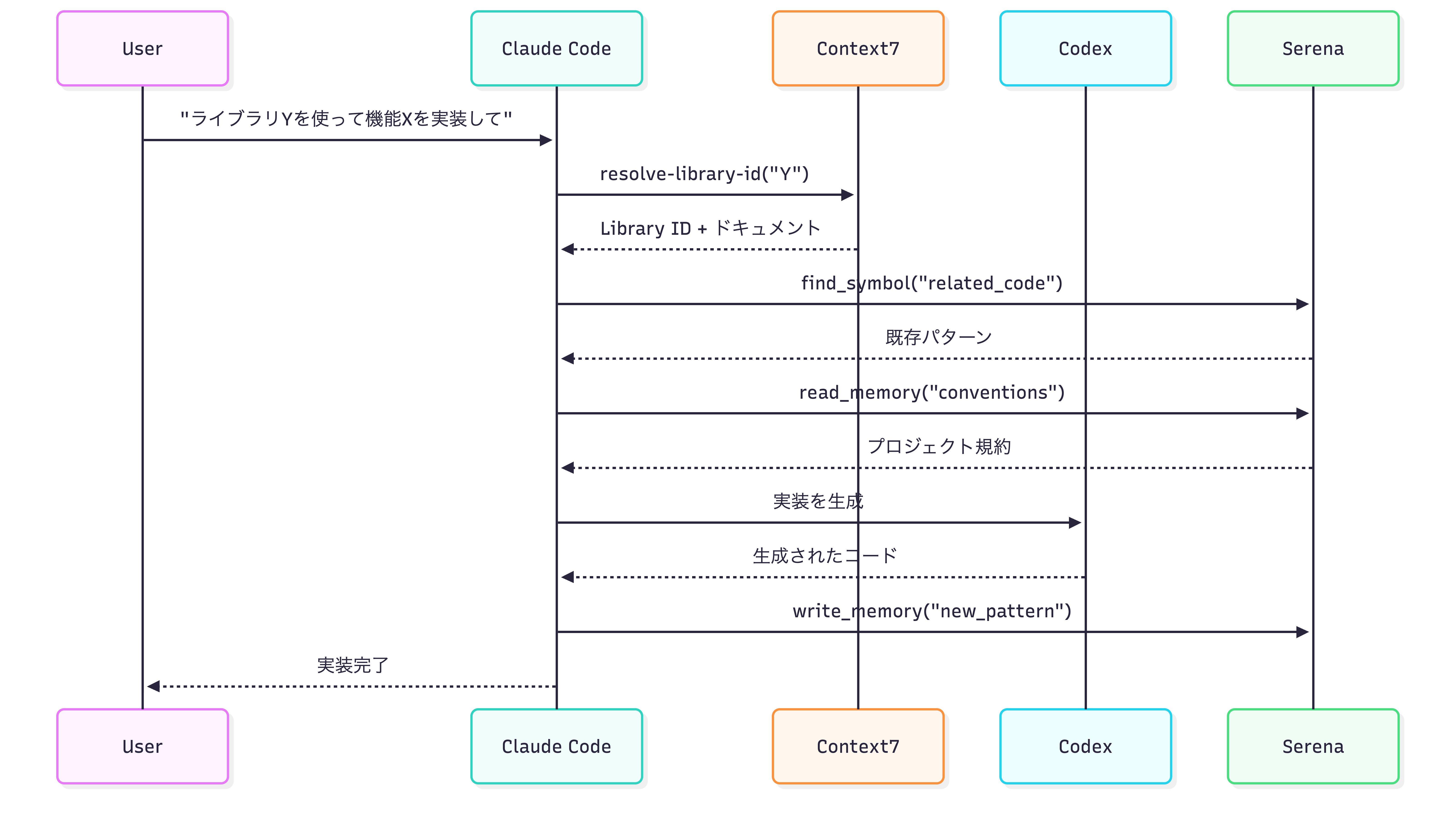
5.2.1. Phase 1: 外部知識取得(Context7)
まずContext7で外部ライブラリの最新ドキュメントを取得します。 resolve-library-id でパッケージ名からライブラリIDを解決し、 get-library-docs でドキュメントを取得します。 topic パラメータで関心領域を絞り込むこともできます。信頼スコア7-10のライブラリを優先することで、信頼性の高いドキュメントを参照できます。
5.2.2. Phase 2: 内部知識取得(Serena)
次にSerenaでプロジェクト固有のパターンを取得します。 find_symbol で関連するコード要素を探索し、 read_memory でプロジェクトの規約やベストプラクティスを読み込みます。 find_referencing_symbols で影響範囲を事前確認することで、安全にコードを変更できます。
Serenaのツールは4カテゴリに分かれます。シンボル検索では get_symbols_overview / find_symbol / find_referencing_symbols でコード要素を探索します。パターン検索では search_for_pattern で正規表現による横断検索をします。コード編集では replace_symbol_body / insert_before_symbol / insert_after_symbol / rename_symbol でシンボル単位を編集します。メモリでは list_memories / read_memory / write_memory / edit_memory / delete_memory で知識を永続化します。
5.2.3. Phase 3: 実装(Codex)
外部知識と内部知識が揃ったら、Codexでコードを生成します。 codex() で会話を開始し、 codex-reply() で継続します。適切な使用場面は、新規ファイル・関数の生成、複雑なリファクタリング、ボイラープレートコードの生成です。
経験的に、Codexはコード生成が得意です。Claude Codeも優れたコード生成能力を持っていますが、Codexに任せたほうがきれいなコードが出てくることが多いと感じています。特にボイラープレートや定型的なコード生成では、その差が顕著です。
重要な制約として、調査・分析にはCodexを使わず、1回の呼び出しで1つの明確なタスクに限定し、マルチファイル編集は避けるようにしています。
5.2.4. Phase 4: 知識永続化(Serena)
実装完了後、新たに発見したパターンや規約を write_memory でSerenaに保存します。次回以降のセッションでも同じ知識を再利用できるため、プロジェクトの規約を毎回説明する手間がなくなります。
この4フェーズの連携により、最新のベストプラクティスを参照しつつ、プロジェクト固有の規約に準拠したコードを生成し、学習した知識を蓄積していけます。
MCP Serverによる機能拡張を理解したところで、次章ではhome-managerによる宣言的管理と安全性の確保について解説します。
6. 運用と安全性
本章では、Claude Code設定の宣言的管理と、安全性を担保するための仕組みについて解説します。
6.1. home-managerによる宣言的管理
Claude Codeの設定はhome-managerで宣言的に管理しています。 programs.claude-code モジュールを中心に、CLAUDE.md、agents/、commands/、skills/、hooks/、scripts/ というディレクトリ構成で整理しています。
programs.claude-code = {
enable = true;
package = nodePkgs."@anthropic-ai/claude-code";
memory.source = ./CLAUDE.md;
settings = {
theme = "dark";
autoUpdates = false;
autoCompactEnabled = true;
enableAllProjectMcpServers = true;
outputStyle = "Explanatory";
};
agents = { ... };
commands = { ... };
skills = { ... };
hooks = { ... };
mcpServers = { ... };
};
agents/commands/skills/hooksの各項目は builtins.readFile でMarkdownファイルを読み込む形式を採用しています。たとえば agents = { code-quality = builtins.readFile ./agents/code-quality.md; } のように記述します。プロンプトの内容をMarkdownで記述できるため可読性が高く、Nixの評価時に文字列として埋め込まれるためファイル単位でのdiffも取りやすくなります。
この宣言的アプローチの最大の利点は再現性です。設定をGitで管理し、 home-manager switch 一発で同一の環境を任意のマシンに展開できます。
6.2. hooksによるポリシー強制
hooksはClaude Codeのツール実行ライフサイクルに介入する仕組みです。 私は2種類のhooksを設定しています。タスク完了通知とコマンドバリデーションです。
6.2.1. hooksの種類
公式ドキュメントでは10種類のhookイベントが定義されていますが、私が使用しているのは4種類です。 PreToolUse はツール実行前に発火し、バリデーションやコマンド検証に使用します。 PostToolUse はツール実行後に発火し、ログ記録や後処理に使用します。 Stop はセッション終了時に発火し、通知やクリーンアップに使用します。 Notification は通知イベントで、外部連携に使用します。
hookスクリプトの終了コード規約として、 exit 0 は処理を許可し、 exit 2 は処理をブロックします(stderrがエラーメッセージとして表示されます)。
6.2.2. enforce-perl hook: コマンドバリデーション
CLAUDE.mdで定義した「perlでテキスト処理」ルールを強制するバリデーションhookを紹介します(hooks/enforce-perl.sh)。
#!/bin/bash
set -euo pipefail
input=$(cat)
tool_name=$(echo "$input" | jq -r '.tool_name // ""')
command=$(echo "$input" | jq -r '.tool_input.command // ""')
if [[ $tool_name != "Bash" ]] || [[ -z $command ]]; then
exit 0
fi
# sed/awk使用を検出してブロック
if echo "$command" | grep -qE '\b(sed|awk)\b'; then
cat >&2 <<'EOF'
❌ sed/awk detected - Use perl instead
Examples:
❌ sed 's/foo/bar/g' file.txt
✅ perl -pe 's/foo/bar/g' file.txt
EOF
exit 2 # Block the command
fi
exit 0 # Allow
\b(sed|awk)\b の正規表現でワードバウンダリを指定し、 sediment のような誤検出を防いでいます。「perlを使え」とCLAUDE.mdに書いてあるのにsedを使ってきたら、hookがブロックして「perlにしてね」と返してくれます。
6.3. permissions と statusline
6.3.1. permissions: 多層防御
permissionsは、Claude Codeが実行できるコマンドを制限するセーフティネットです。Defense in Depth(多層防御)の考え方で、サンドボックス(第1層)、permissions deny(第2層)、hooks validation(第3層)の3層構造で保護しています。
危険なコマンドを6つのカテゴリに分類して禁止しています。ファイル破壊( rm -rf / など)、システムコマンド( shutdown / reboot )、ディスク操作( dd / mkfs )です。さらにプロセス制御( killall / pkill )、ネットワークリスナー( nc -l )、権限昇格( sudo rm / chmod 777 )も禁止しています。
6.3.2. statusline: セッション状態の可視化
statuslineはClaude Codeのセッション状態をリアルタイムで可視化する機能です(scripts/statusline.sh)。モデル名、カレントディレクトリ、Gitブランチ、トークン使用量と割合を表示します。
トークン使用率に応じて色を変えることで、コンパクション発生前に警告を出せます。70%未満は緑(十分な余裕あり)、70-89%は黄色(注意が必要)、90%以上は赤(コンパクション間近)で表示されます。
ここまでの章で、プロンプト設計、マルチエージェント構成、MCPによる機能拡張、そして運用と安全性について解説してきました。次章では、運用して得られた結果と所感を共有します。
7. 得られた結果・所感
このワークフローを使い始めて、開発体験が明らかに変わりました。
一番大きいのは、Claude Codeの振る舞いが予測可能になったことです。以前は「今日はどんな形式で返ってくるかな」と毎回ドキドキしていましたが、XMLで構造化したプロンプトと専門エージェントへの委譲により、期待とおりの出力が得られるようになりました。
セキュリティレビューをお願いすれば、ちゃんとセキュリティの観点だけでレビューしてくれます。コードスタイルの指摘が混在することもなくなりました。これが地味に嬉しい。
/define → /execute → /feedback というフローも気に入っています。調査と実装が明確に分離されているので、「調べてたらいつの間にかファイルが変わってた」という事故がなくなりました。安心して「とことん調べて」といえるのは大きい。
一方で、Serenaが本当に必要なのかは正直まだわかりません。シンボルレベルの操作でトークン効率が上がるとは書きましたが、Claude Code標準のGlob/Grep/Readでも十分な気がしています。LSP設定やオンボーディングの手間を考えると、その複雑さに見合うリターンがあるのか。今後の運用で見極めていきたいところです。
8. おわりに
私のClaude Codeワークフローを紹介しました。
「セキュリティレビューなのにコードスタイルの指摘ばかり」という不満から始まった試行錯誤が、気づけばマルチエージェントシステムになっていました。ここまで作り込むとは思っていませんでしたが、AIツールの設定をソフトウェアプロジェクトのように育てていくのは楽しいものです。
やりたいことはまだまだあります。プロンプト入力の英語統一、Context7とSerenaの使い分け基準の明確化、クロスプロジェクトでの知識共有など。
本記事で紹介した設定はGitHubリポジトリで公開しています。Nixユーザーの方はそのまま参考にできるはずです。公式ドキュメントと合わせてどうぞ。